The program update tape (PUT) 10 enhancements to TPF collection support (TPFCS) fall into three categories:
TPFCS is now more efficient because it will reuse long-term pool records that it has released. Because of this enhancement, applications that use TPFCS will no longer flush through pool records as quickly. The reuse of long-term pool records generally works as follows:
TPFCS maintains a pool reuse table for each subsystem. Each table is large enough to hold 100 file addresses. When TPFCS no longer needs a long-term pool record, it stores the file address of the record in the appropriate reuse table instead of releasing it back to the system. When TPFCS needs to obtain a new long-term pool record, before using the GETFC macro to allocate a new record, it looks in the appropriate reuse table to see if there is a pool record it can reuse instead. Because the tables hold only 100 file addresses, if an application causes many more TPFCS pool record releases than allocates, it may not fully take advantage of these tables. For example, if an application causes 200 records to be marked for release and then needs to use an additional 200 records, TPFCS can reuse only 100 file addresses; the others will actually be released and reallocated. On the other hand, if an application causes 50 records to be marked for deletion and then an additional 50 records are needed, and this happens four times, TPFCS will be able to reuse all 200 file addresses.
There are additional constraints as to when these tables are used (for example, recoup is not active, there are no open commit scopes for the entry control block (ECB) under which TPFCS is running, and so on). Additional details are provided in the TPF Database Reference publication.
When you install PUT 10, you will have the capability to display the contents of a directory entry for a specific relative record number (RRN) or the path information for either a key or an RRN by using the new ZBROW PATH functional message. You will also be able to display the record number and displacement in the record for a specific index or relative byte address (RBA). These enhancements, together with the documentation that was provided with PUT 9 in TPF Database Reference about the internals of TPFCS collections, will help you obtain a better understanding of how collection data is stored in a TPFCS database and will also help with debugging problems.
Applications that use TPFCS will now have greater flexibility. First of all, the maximum number of bytes that can be processed for a binary large object (BLOB) has been increased from 32 KB to 4 MB for the following functions:
Second, applications can now view and process the same collection in different ways because of enhanced key path support. Are you wondering what key path support is and how it was enhanced? Just read on . . .
The new PUT 10 key path enhancements will enable you to search for and access data in a collection by using a data field in addition to a key or sort field.
Before PUT 10, there was only one type of key path, called a primary key path. A primary key path forms the structure of all keyed and sorted collections. Primary key paths are sorted in ascending binary value by the primary key or sort field, and they can be either unique or nonunique depending on the collection type. PUT 10 enhancements provide a new type of key path, called the alternate key path. Alternate key paths support nonunique key path fields (keys) and are sorted in ascending binary value based on the key path field.
TPFCS supports primary and alternate key paths for the following persistent keyed and sorted collections:
From an application perspective, sorted bag and sorted set collections do not have primary keys, but only have sort fields. The sort field of these collections is used internally by TPFCS as if it were a primary key in order to form the primary key path structure.
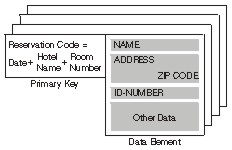
To understand how alternate key paths work, consider an example in which an application has created a key sorted set (previously known as a dictionary) to manage hotel reservations. The (primary) key of the collection is a reservation code comprised of the date, hotel name, and room number. Each key is unique because only one reservation can be made for each room in a particular hotel for a given day. The layout of a data element in the collection contains many fields, but those shown in the following figure are of special interest to the application:
The NAME field identifies the person who made the reservation. The ADDRESS field is the home address of that person, and a field for the ZIP CODE is included. The ID-NUMBER field is used as another means to identify the person making the reservation. Depending on the application, this field may contain a social security number, a home telephone number, or a credit card number. Even though the primary key for this collection is unique, these data fields are not. For example, two people can have the same name, or the same person can have more than one reservation.
Before PUT 10, the key sorted set collection used in our example would have been sorted only on the unique primary key, as shown in the following figure:
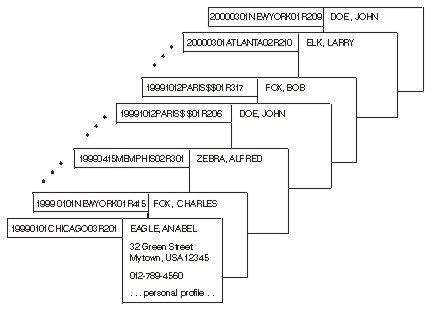
If the application wanted to search for all reservations under a given name, it would either have to read through every element in the collection and check the NAME field for each, or it would have to use the TO2_asSortedCollection function to create another collection with the same data, sorted by name. If this type of operation is not done very often, these approaches might be satisfactory. However, if this type of operation happens more than occasionally, an application that reads through each element would be costly in terms of performance. An application that creates a copy of the collection, sorted by name, would either have to repeatedly create and delete the new sorted collection, or it would have to continuously maintain multiple collections containing the same data. These approaches could impact system performance and system resources. With alternate key path support, the application could add an alternate key path to the same collection, in which the NAME field in the data is used as a key. Adding a key path does not change the contents of the collection, and TPFCS will automatically maintain multiple key paths associated with a collection. In addition to accessing the collection by using the primary key path, the application could now access the same collection by using the alternate key path, in which case the collection would appear to be sorted by the NAME field as shown in the following figure:
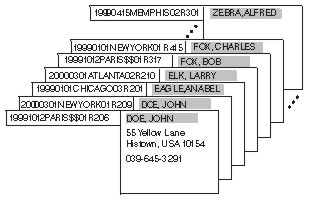
To retrieve all elements in a collection that contain a given name, the application would create a cursor for the collection, set the cursor to use the alternate key path, and then use the TO2_locate function supplying the name it wants to search for as the key. It could then advance the cursor one position at a time to access all elements that contain that name. Note that the primary key is still shown in the figure because you can still determine the primary key of a data element currently referenced by your cursor. The TO2_key and TO2_keyWithBuffer functions will always return the primary key even if the cursor is set to use an alternate key path. To determine the key for the key path currently in use, you can use the new TO2_getCurrentKey and TO2_getCurrentKeyWithBuffer functions. In our example, TO2_getCurrentKey or TO2_getCurrentKeyWithBuffer would return "DOE, JOHN " if the cursor had been set to use the NAME alternate key path and had been positioned to the first element. The TO2_key or TO2_keyWithBuffer functions would still return the primary key of 19991012PARIS$$01R206 even though the cursor had been set to no longer use the primary key path.
The application can also add alternate key paths to the same collection by using other fields as well. For example, alternate key paths could be added for the ZIP CODE and ID-NUMBER fields. The application could then access the same collection at any given time as if it were ordered by these key paths.
A maximum of 16 alternate key paths (in addition to the primary key path) can be defined for a given collection. The TO2_atKey, TO2_atKeyPut, TO2_atNewKeyPut, and TO2_removeKey functions use only the primary key path for processing data. As was the case in our example, you can use alternate key paths only with cursors.
You are probably wondering how key paths are added. Primary key paths are automatically established when a collection is created in a TPFCS database. Alternate key paths are added to a collection by using the TO2_addKeyPath function. Using the TO2_addKeyPath function, the application program assigns a name for the new key path and specifies the displacement and length of the field in the data element that the key path will reference. If a particular data element is too short to contain the entire field, it will still be included in the key path as if bytes of zero were concatenated at the end for the remaining length of the field. Key paths are built automatically by an asynchronous task if the collection already exists and contains data elements. The key path is not usable until the build process has completed successfully. While the key path build process is in progress, an error code (TO2_ERROR_KEYPATH_BUILD_ACTIVE) is returned if an application attempts to access the collection using that path.
After the key path has been added, TPFCS will automatically maintain it whenever the collection is updated. Therefore, collections with alternate key paths will take longer to update because they have to maintain the internal structures of every key path.
In our example, we saw how an application could view and access the same collection in different ways depending on the key path in use. Once alternate key paths have been added to a collection, the application is free to access the collection using either the primary or any of the alternate key paths it has added. How is this done? First of all, it is important to remember that all noncursor functions in TPFCS automatically access elements using only the primary key path. However, an application program can use a cursor to access a collection using either the primary or any of the alternate key paths. To use a key path, the application program creates a cursor by using either the TO2_createCursor or TO2_createReadWriteCursor function. Initially, the cursor uses the primary key path by default. The application can change the key path and assign an alternate key path to the cursor by using the TO2_setKeyPath function and by specifying a key path name.
The application program can also issue a TO2_setKeyPath call with the TO2_PRIME_KEYPATH name to reset the cursor to use the primary key path.
In addition to adding alternate key paths to a collection, applications can remove them as well. To remove an alternate key path from the collection, the application program issues a TO2_removeKeyPath request specifying the name of the key path to remove. The TO2_removeKeyPath function deletes the key path from the collection and releases the resources of the key path back to the system, or reuses them as discussed previously.
Because the primary key path dictates the fundamental structure of a collection, you cannot remove the primary key path from a collection.
In addition to using application programs to work with key paths, some key path functions are also available through functional messages. The ZBROW functional messages have been enhanced to allow you to:
For additional information about enhancements discussed in this article, see the following publications:
| Information | Book |
|---|---|
| Adding, using, and removing key paths | TPF Application Programming |
| APIs mentioned in this article | TPF C/C++ Language Support User's Guide |
| APIs not mentioned in this article | TPF C/C++ Language Support User's Guide |
| TPFCS internals | TPF Database Reference (Chapter 17) |
| TPFCS functional messages | TPF Operations |
| Installing PUT 10 | TPF Migration Guide: Program Update Tapes |
We hope you will find the TPFCS PUT 10 enhancements useful. After you have gained some "hands-on" experience with TPFCS, we encourage you to send us some feedback and submit new requirements for future enhancements.