(TPF Persistent) Collections Corner
by Michele Dalbo, IBM TPF ID Core Team, and Daniel Jacobs, IBM TPF Development
By now, I am sure that everyone has heard about the availability of TPF persistent collections support (fondly referred to as TO2 by some users) on TPF PUT7. I am sure that everyone has heard how it is an amazing tool that allows rapid application development while increasing quality and lowering costs. So now, the question that everyone asks is “How can I take advantage of the amazing and unbelievable benefits that this product provides?”
Persistent Collections 101
Before we discuss the answer to the previous question, let's review exactly what persistent
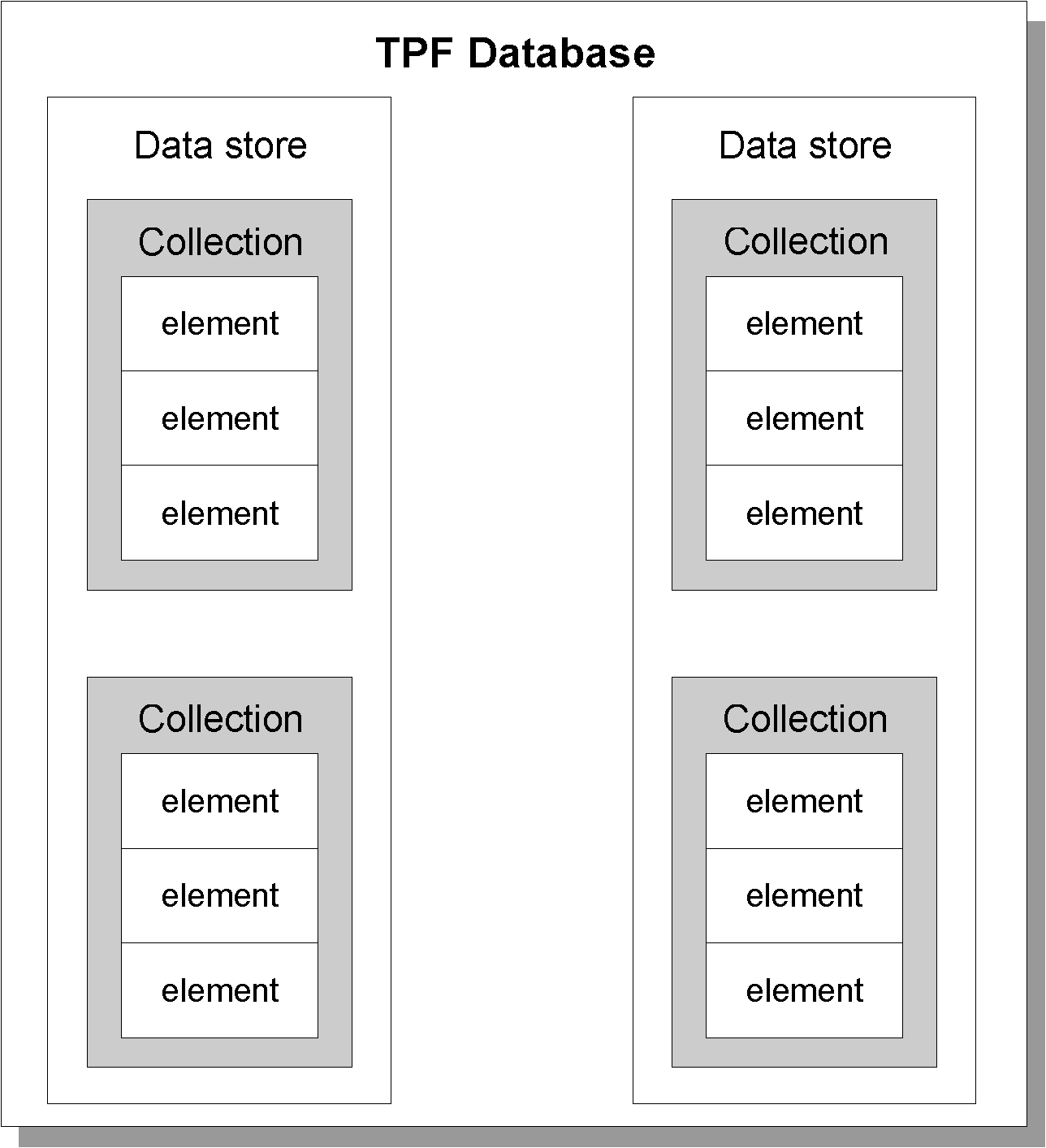
collections are. A collection is an abstract representation of data that has common attributes and
common functions that can be applied to the data. Persistent collections are collections that are
available until they are specifically deleted. Each unit of data in a collection is called an element,
and collections generally can hold as many as 2 GB of elements. The maximum size of an element
can vary from 1 byte to 4 KB depending on the collection type. Groups of related collections are
stored in an entity known as a data store, and a persistent collections database consists of all of
the data stores on the TPF system. To relate this to terms that you might be more familiar with, a
collection is like a file, and the elements within a collection are like records within a file. A data
store can be considered to be groups of related files, and all of these groups put together forms a
database.
To summarize, a persistent collections database might look something like the following:
The TPF persistent collections library contains 11 different collection types. Each collection type has a unique set of characteristics. For example, some collections have a relative order between the elements (that is, one element is before or after another one in the collection), while elements in other collections are randomly ordered. Some collections have keys, meaning that with a single application programming interface (API) call, a particular element can be located using a search criteria. Some collections allow elements to have duplicate values or keys while other collections require each element to be unique. Collections are created dynamically by the application without any need for predefined data definitions.
Each collection type also has predefined functions that can be applied to the data in the collections. There are over 125 different functions that can be applied to the data for creation, deletion, and manipulation of data. Some functions can be applied to all collection types and some can only be applied to one collection type. How do you know what works with what? That is what our documentation is for! See IBM TPF C/C++ Language Support User's Guide for information about these functions.
Now that we have covered the basics, we will try to answer the original question that we had about how to take advantage of this product. To do this, we are presenting the first in a series of newsletter articles that talk about each of the collection types available in the TPF persistent collections library. In each issue, there will be a highlighted “collection of the month” with information about that collection and a description of potential applications for each collection type. Some of the examples may be fairly practical; others may be, well, stretching the imagination somewhat. Hopefully, these articles will help you to understand the characteristics, behavior, and overall capabilities of the collections, and give you ideas on how you can use TPF persistent collections at your installation.
With that, we introduce you to the first featured collection of the month.
Array
Characteristics
An array is a collection of ordered elements that are a fixed length and are accessed by relative
position (index) in the array starting with index 1. Multiple elements can contain the same data, and
new elements can only be added to the end of the collection. Persistent collections support zeros
out elements that the application deletes instead of actually removing the elements and shifting the
remaining elements.
Advantages
If you have data that does not have an inherent identifier, but an identifier is desired, an array would
be a good candidate to represent such data because the array index assigned to each element acts
as an identifier. Arrays are also appropriate for data that tends to grow without much deletion (or
zeroing out), although it would be fairly simple to reuse array indexes when data is deleted as long
as the model allows “identifiers” to be reassigned.
Examples
To illustrate how an array might be used, let's say we were running a health clinic that administers
flu shots, measles shots, and so on. Fifteen-minute slots are reserved for each patient. Why would
an array be a good choice to represent this data? Well, each day could be represented by an array,
with each element in the array representing a time slot. There is an implied order between the time
slots (chronologically), just as there is an implied order between relative index positions in the array.
Obviously, time slots cannot be deleted or inserted in the middle of the schedule, but the potential
to work overtime and add slots at the end of the day is possible (to the dismay of the workers).
Arrays do not have keys or element equality, but schedules are usually searched by time, not
patient name, so this is compatible with the model. Furthermore, the data contained within the array
can be non-unique, which would allow a single patient to occupy more than one slot, perhaps
because they need to get a flu and measles shot.
Another example of using an array is a program for keeping track of seat assignments on an airplane, train, or bus. The program addresses array elements by using the seat number as an index to the corresponding entry in the array. When the seat is assigned, the name of the passenger is entered using the seat number as the index. You can determine the name of the passenger assigned to a specific seat by accessing the entry of the array indexed by the seat number. However, you cannot determine empty seats except by iterating through the array and testing for an empty entry.
I could go on and on with more examples for arrays, but I think that I will just leave it up to you to think of how you can use array collections to improve productivity at your installation. Now, as an added bonus for those of you who have made it this far, we will now talk about yet another collection, and one of our favorites . . . the BLOB.
BLOB
Characteristics
The collection with the best name is definitely the BLOB. No, this is not the same BLOB that
almost won an Academy Award in “Monsters of the Night.” This is a binary large object, also
known as a byteArray. A BLOB is a special array collection, and it has much in common with
arrays. BLOBs have fixed size elements (with each element being exactly 1 byte in size) that are
accessed by a relative position, the relative byte address (RBA). New elements can only be added
to the end of a BLOB, and elements are zeroed out instead of deleted. Elements are non-unique
(which makes sense considering that if each element is only 1 byte in size, there are only 256 unique
values anyway!).
One very important characteristic unique to BLOBs is that operations can be performed on ranges of elements. Data can be read and updated in its entirety or part by part, not just one element at a time. Even more important to remember is the amount of data that can be manipulated at one time can exceed 4K! Currently, up to 32K of data can be read or stored with a single API call, and up to 2 GB of data can be stored in a single BLOB!
Advantages
The best use for a BLOB is, well, anything! That is what makes a BLOB so great! With most
collection types, TPF persistent collections has no knowledge of the format of the data, but the
elements are separated from each other. With a BLOB, TPF persistent collections does not have
any knowledge of the format of the data, but individual elements (bytes) can also be combined to
form ranges of elements, giving the application even greater flexibility. The best use for a BLOB is
for a stream of data, regardless of the format of the data. An application could store numerous
formatted records in a BLOB. Entire structures that exceed 4 K can be saved and retrieved with a
single API call! The data could also be plain text or data with varying formats, such as images,
sounds, or anything else that can be represented by 0's and 1's (which is just about anything!). In
fact, you could even build an entire file system using a TPF persistent collections BLOB. (Now,
why does that idea sound familiar?)
Examples
One example of using a BLOB might be if you are the head of a secret spy agency and you need to
enhance security. You might want to attach an agent's picture, fingerprints, or voice to their file so
that each agent can be positively identified. Any of these means of identifying someone can be
stored and retrieved using a BLOB. Another example of using a BLOB might be if a hospital wants
to attach a patient's X-rays to their medical file. The X-ray must be available to be read in its
entirety or part by part. In fact, there may sometime be a reason to update part of the image.
(Disclaimer: We are not suggesting that a doctor will “touch up” an X-ray for a particular reason..)
By using a BLOB to represent a patient X-ray, a range of bytes (that is, a part of an X-ray image)
can be read or updated with a single, convenient API call. Now that you know a BLOB is not a
monster, how can you put this friendly collection to work for you?
Coming Soon
Well, that is all, at least for this issue. Watch this column for ideas about using collections that have
a user-defined order to them, coming soon to a Technical Newsletter near you!